Desvendando o Cache-Aside Pattern
Alguém lhe indaga com a seguinte situação: "Seu backend está recebendo ~1000 requisições por minuto, e cada uma delas bate no banco para recuperar o mesmo recurso, a infraestrutura atual já está no seu limite e não podemos provisionar mais cpu para o banco de dados", para resolver este problema, é bem provável que você sugira Cache-Aside, e não está errado. O que quero lhe mostrar neste artigo/lab, é que Cache-Aside não é somente ter um banco de dados em memória aliviando a carga do banco principal, existem várias armadilhas dentro deste processo, que você deve conhecer ao implementar este padrão.
O que é Cache-Aside Pattern
Para garantir que estamos juntos, aqui vai uma breve explicação.
O padrão Cache-Aside, de forma simplória, funciona da seguinte maneira:
-
Problema: Muitas requisições estão sendo feitas para o mesmo endpoint, e todas recuperam algum recurso do banco de dados, isto é lento (HD/SSD), e custoso (uso de CPU). Aplicação inteira fica sobrecarregada.
-
Solução Padrão: Implementamos um banco de dados em memória (ex Redis), que é extremamente mais rápido (opera na memória RAM), e consome muito menos recursos do servidor.
-
Novo Fluxo: Agora a primeira requisição bate no banco, recupera o recurso, salva no cache e retorna para o usuário. As requisições subsequentes buscam a informação diretamente no cache, sem precisar chegar até o banco principal.
Uma imagem pode lhe ajudar com o entendimento do fluxo:
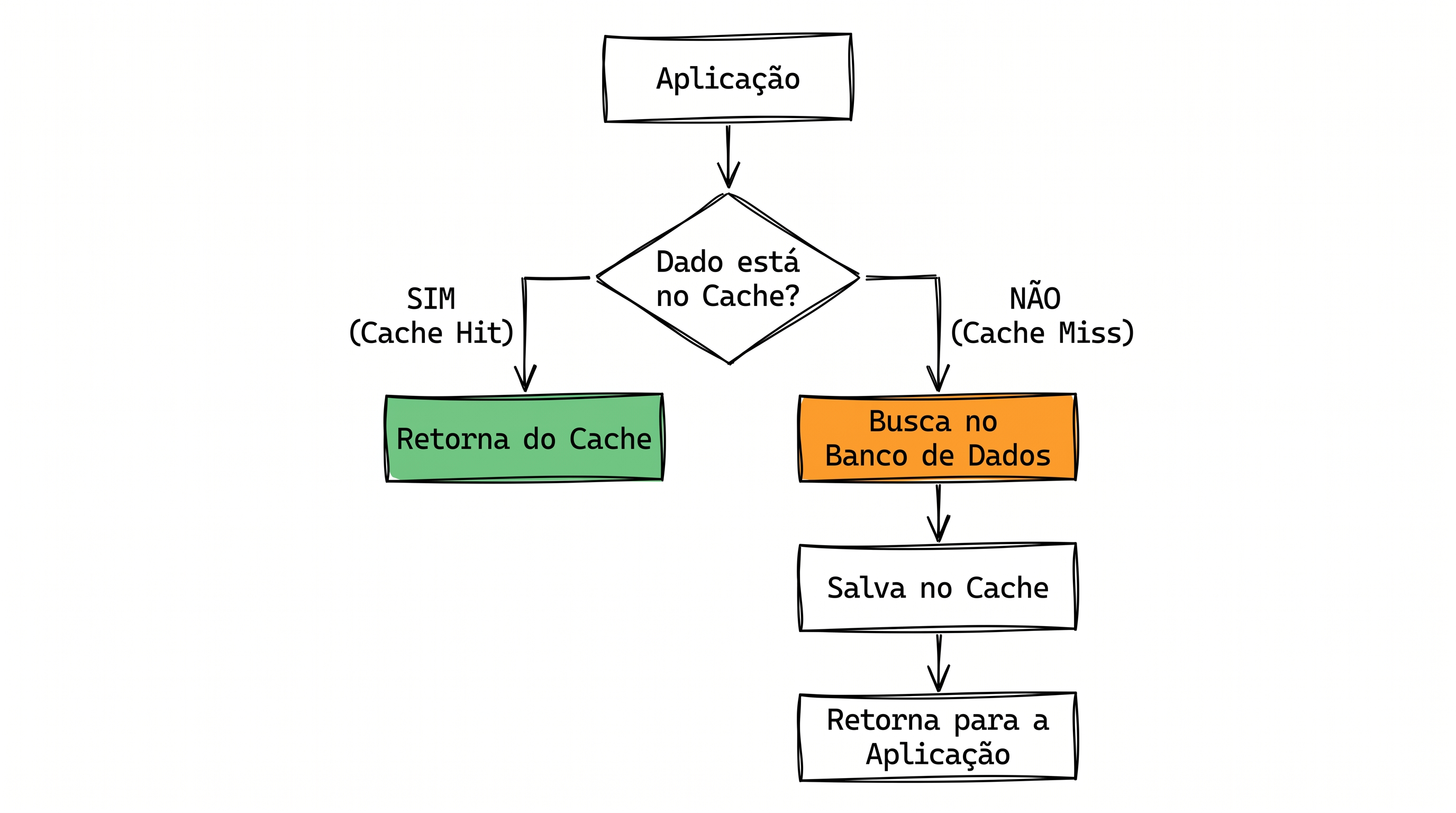
Agora que estamos alinhados, podemos prosseguir.
1. Setup
Vou simular um ambiente local para realizarmos nossos testes, implementarei a aplicação com nodejs, o banco de dados principal com postgres, e para cache usarei o banco em memória redis.
Iniciando a aplicação node:
npm init -y
Instalando nossas dependências:
npm install express ioredis pg
Vamos iniciar os containers
Para rodarmos de maneira simples o banco postgres e o banco redis, crie o arquivo docker-compose.yml na raiz do projeto:
services:
postgres:
image: postgres:16
container_name: cache-aside-postgres
environment:
POSTGRES_USER: postgres
POSTGRES_PASSWORD: postgres
POSTGRES_DB: lab
ports:
- "5432:5432"
volumes:
- postgres_data:/var/lib/postgresql/data
healthcheck:
test: ["CMD-SHELL", "pg_isready -U postgres"]
interval: 5s
timeout: 5s
retries: 5
redis:
image: redis:7
container_name: cache-aside-redis
ports:
- "6379:6379"
healthcheck:
test: ["CMD", "redis-cli", "ping"]
interval: 5s
timeout: 5s
retries: 5
volumes:
postgres_data:
Para rodar os dois containers:
docker-compose up -d
Vamos criar uma tabela chamada produtos e adicionar 500 mil registros, no terminal rode:
docker exec -it cache-aside-postgres psql -U postgres -d lab
Em seguida cole o SQL abaixo e pressione Enter:
CREATE TABLE IF NOT EXISTS produtos (
id SERIAL PRIMARY KEY,
nome VARCHAR(255) NOT NULL,
preco NUMERIC(10,2) NOT NULL,
descricao TEXT,
categoria VARCHAR(100),
criado_em TIMESTAMP DEFAULT NOW()
);
INSERT INTO produtos (nome, preco, descricao, categoria)
SELECT
'Produto ' || g,
(RANDOM() * 1000)::NUMERIC(10,2),
'Descrição detalhada do produto número ' || g || '. Este produto possui características únicas que o diferenciam no mercado.',
CASE (g % 5)
WHEN 0 THEN 'eletrônicos'
WHEN 1 THEN 'roupas'
WHEN 2 THEN 'alimentos'
WHEN 3 THEN 'livros'
WHEN 4 THEN 'ferramentas'
END
FROM generate_series(1, 500000) AS g;
Para podermos iniciar nossos testes, crie o arquivo src/index.js:
const express = require("express");
const { Pool } = require("pg");
const Redis = require("ioredis");
const app = express();
app.use(express.json());
// Conexão com Postgres
const db = new Pool({
host: "localhost",
port: 5432,
user: "postgres",
password: "postgres",
database: "lab",
});
// Conexão com Redis
const redis = new Redis({
host: "localhost",
port: 6379,
});
// ==========================================
// Seção 1 — Sem cache (direto no banco)
// ==========================================
app.get("/produto/:id", async (req, res) => {
const { id } = req.params;
const inicio = Date.now();
try {
const resultado = await db.query("SELECT * FROM produtos WHERE id = $1", [
id,
]);
if (resultado.rows.length === 0) {
return res.status(404).json({ erro: "Produto não encontrado" });
}
const tempo = Date.now() - inicio;
console.log(`[DB] GET /produto/${id} - ${tempo}ms`);
res.json({
source: "database",
tempo_ms: tempo,
produto: resultado.rows[0],
});
} catch (erro) {
console.error("Erro ao consultar banco:", erro.message);
res.status(500).json({ erro: "Erro interno" });
}
});
// ==========================================
// Seção 2 — Com Cache-Aside
// ==========================================
app.get("/produto-cached/:id", async (req, res) => {
const { id } = req.params;
const inicio = Date.now();
const chaveCache = `produto:${id}`;
try {
// 1. Tenta buscar no Redis
const cacheado = await redis.get(chaveCache);
if (cacheado) {
const tempo = Date.now() - inicio;
console.log(`[CACHE HIT] GET /produto-cached/${id} - ${tempo}ms`);
return res.json({
source: "cache",
tempo_ms: tempo,
produto: JSON.parse(cacheado),
});
}
// 2. Cache miss — busca no banco
const resultado = await db.query("SELECT * FROM produtos WHERE id = $1", [
id,
]);
if (resultado.rows.length === 0) {
return res.status(404).json({ erro: "Produto não encontrado" });
}
const produto = resultado.rows[0];
// 3. Salva no Redis com TTL de 60 segundos
await redis.set(chaveCache, JSON.stringify(produto), "EX", 60);
const tempo = Date.now() - inicio;
console.log(`[CACHE MISS] GET /produto-cached/${id} - ${tempo}ms`);
res.json({
source: "database",
tempo_ms: tempo,
produto,
});
} catch (erro) {
console.error("Erro:", erro.message);
res.status(500).json({ erro: "Erro interno" });
}
});
// ==========================================
// Inicia o servidor
// ==========================================
app.listen(3000, () => {
console.log("Servidor rodando em http://localhost:3000");
console.log("Endpoints:");
console.log(" GET /produto/:id (sem cache)");
console.log(" GET /produto-cached/:id (com cache-aside)");
});
Você pode ler com calma o código acima, acredito que os comentários lhe ajudem a entender.
2. Teste Real
Primeiro vamos realizar requisições no endpoint que não utiliza cache:
autocannon -c 10 -d 10 http://localhost:3000/produto/42
O código acima irá criar 10 conexões simultâneas e irá realizar o máximo de requisições que conseguir dentro de 10 segundos. (número varia de acordo com a velocidade do servidor)
O autocannon pode ser instalado globalmente usando
npm i -g autocannon.
Aguardamos 10 segundos, e podemos anotar alguns resultados:
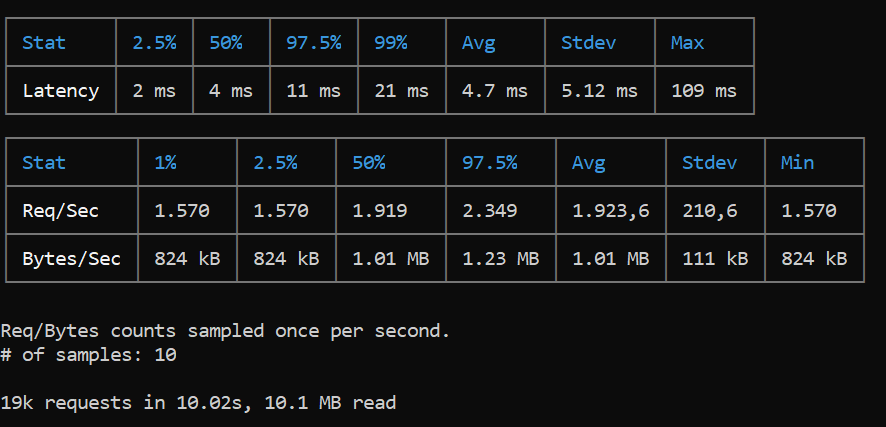
- Latência média das requisições: 4.7ms
- Latência p99: 21ms
- Requisições por segundo: 1923
- Total de requisições em 10 segundos: 19k
Agora vamos realizar o teste usando o cache, primeiro fazemos uma requisição isolada para que o nosso programa salve a informação no Redis:
curl http://localhost:3000/produto-cached/42
Agora podemos realizar nossa bateria:
autocannon -c 10 -d 10 http://localhost:3000/produto-cached/42
Vamos analisar os resultados:
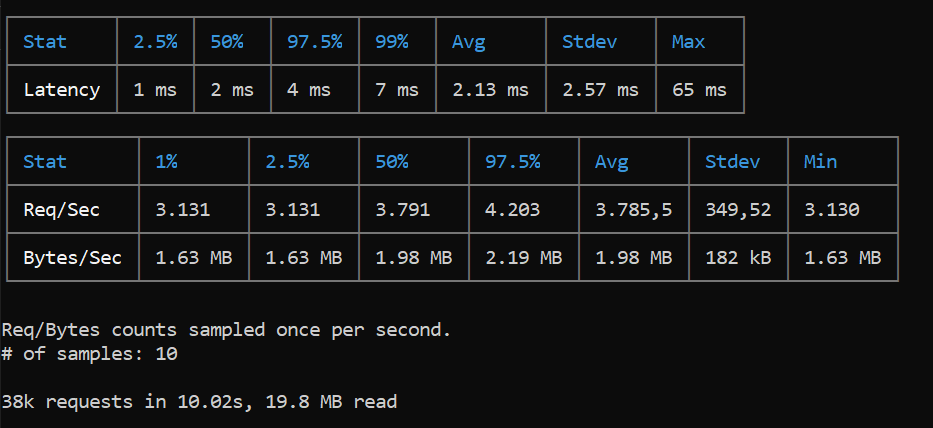
- Latência média das requisições: 2.13ms 2.2x mais rápido
- Latência p99: 7ms 3x mais rápido
- Requisições por segundo: 3789 2x mais capacidade
- Total de requisições em 10 segundos: 38k 2x mais requisições
"Nossos testes em ambiente local tiveram uma melhoria de 2x, em ambiente real de produção, com latência de rede entre aplicação e banco esses números poderiam facilmente ter passado de 10x, chegando em uma melhoria em alguns casos de até 50x".
3. Cache Stampede
Agora você tem cache implementado e tudo parece seguro, porém seu cache expira durante um pico de tráfego, um problema enorme...
100 requisições chegam na aplicação de forma simultânea, e como ocorrem com diferença de tempo de milissegundos uma da outra, todas as 100 dão MISS para o cache, e todas elas batem no banco.
Para vermos isso ocorrendo, crie o arquivo src/simular-stampede:
const endpoint = process.argv[2] || "produto-cached";
const id = 42;
const numRequisicoes = 100;
async function disparar() {
console.log(
`\nDisparando ${numRequisicoes} requests simultâneas em /${endpoint}/${id}\n`,
);
// Limpa o cache primeiro pra forçar o miss
const Redis = require("ioredis");
const redis = new Redis();
await redis.del(`produto:${id}`);
await redis.del(`lock:produto:${id}`);
await redis.quit();
const inicio = Date.now();
const promises = Array.from({ length: numRequisicoes }, () =>
fetch(`http://localhost:3000/${endpoint}/${id}`)
.then((r) => r.json())
.then((data) => data.source)
.catch((err) => "ERROR"),
);
const resultados = await Promise.all(promises);
const tempo = Date.now() - inicio;
// Conta as fontes
const contagem = resultados.reduce((acc, fonte) => {
acc[fonte] = (acc[fonte] || 0) + 1;
return acc;
}, {});
console.log(`Tempo total: ${tempo}ms`);
console.log(`Resultados por fonte:`);
Object.entries(contagem).forEach(([fonte, qtd]) => {
console.log(` ${fonte}: ${qtd}`);
});
}
disparar();
Podemos executar o arquivo para disparar 100 requisições que vão chegar praticamente juntas ao nosso endpoint:
node src/simular-stampede.js produto-cached
O resultado no console:
Disparando 100 requests simultâneas em /produto-cached/42
Tempo total: 161ms
Resultados por fonte:
database: 100
Seu cache expirou e todas as 100 requisições bateram no banco de dados, nenhuma foi cacheada pois quando a requisição número 100 chegou, a número 1 ainda não teve tempo hábil de salvar a informação no cache. Dependendo da resistência do seu banco e da quantidade de requisições, sua aplicação poderia ter morrido nesse intervalo de alguns milissegundos.
Para evitarmos esse comportamento, podemos aplicar o conceito de lock distribuído, apenas uma requisição bate no banco, e as outras aguardam o cache ser populado.
Adicione o novo endpoint no arquivo src/index.js:
// ==========================================
// Seção 3 — Cache-Aside com lock (anti-stampede)
// ==========================================
app.get("/produto-locked/:id", async (req, res) => {
const { id } = req.params;
const inicio = Date.now();
const chaveCache = `produto:${id}`;
const chaveLock = `lock:produto:${id}`;
try {
// 1. Tenta buscar no Redis
const cacheado = await redis.get(chaveCache);
if (cacheado) {
const tempo = Date.now() - inicio;
console.log(`[CACHE HIT] GET /produto-locked/${id} - ${tempo}ms`);
return res.json({
source: "cache",
tempo_ms: tempo,
produto: JSON.parse(cacheado),
});
}
// 2. Cache miss — tenta adquirir o lock
// SET com NX (só seta se não existir) e EX (TTL de 5s pra evitar deadlock)
const lockAdquirido = await redis.set(chaveLock, "1", "EX", 5, "NX");
if (lockAdquirido) {
// 2a. Eu ganhei o lock — sou o único que vai no banco
try {
console.log(`[LOCK ACQUIRED] produto:${id} - buscando no banco`);
const resultado = await db.query(
"SELECT * FROM produtos WHERE id = $1",
[id],
);
if (resultado.rows.length === 0) {
await redis.del(chaveLock);
return res.status(404).json({ erro: "Produto não encontrado" });
}
const produto = resultado.rows[0];
// Popula o cache
await redis.set(chaveCache, JSON.stringify(produto), "EX", 60);
const tempo = Date.now() - inicio;
console.log(
`[CACHE MISS + LOCK] GET /produto-locked/${id} - ${tempo}ms`,
);
res.json({
source: "database",
tempo_ms: tempo,
produto,
});
} finally {
// Libera o lock (sempre, mesmo se der erro)
await redis.del(chaveLock);
}
} else {
// 2b. Não ganhei o lock — espero o cache ser populado
console.log(`[WAITING LOCK] produto:${id} - aguardando outro request`);
const cacheado = await aguardarCache(chaveCache, 3000);
if (cacheado) {
const tempo = Date.now() - inicio;
console.log(
`[CACHE HIT APÓS ESPERA] GET /produto-locked/${id} - ${tempo}ms`,
);
return res.json({
source: "cache_after_wait",
tempo_ms: tempo,
produto: JSON.parse(cacheado),
});
}
// Timeout esperando o cache — fallback (vai no banco mesmo)
console.log(`[TIMEOUT LOCK] produto:${id} - fallback pro banco`);
const resultado = await db.query("SELECT * FROM produtos WHERE id = $1", [
id,
]);
if (resultado.rows.length === 0) {
return res.status(404).json({ erro: "Produto não encontrado" });
}
const tempo = Date.now() - inicio;
res.json({
source: "database_fallback",
tempo_ms: tempo,
produto: resultado.rows[0],
});
}
} catch (erro) {
console.error("Erro:", erro.message);
res.status(500).json({ erro: "Erro interno" });
}
});
// Helper: faz polling no Redis até o cache aparecer ou dar timeout
async function aguardarCache(chave, timeoutMs) {
const intervalo = 50; // checa a cada 50ms
const tentativas = Math.floor(timeoutMs / intervalo);
for (let i = 0; i < tentativas; i++) {
const valor = await redis.get(chave);
if (valor) return valor;
await new Promise((resolve) => setTimeout(resolve, intervalo));
}
return null;
}
Lembre de adicionar no app.listen:
console.log(" GET /produto-locked/:id (cache-aside com lock)");
Agora vamos testar as 100 requisições novamente:
node src/simular-stampede.js produto-locked
O resultado que tivemos foi totalmente o contrário, apenas 1 requisição bateu no banco, as outras 99 buscaram resposta diretamente no cache.
Disparando 100 requests simultâneas em /produto-locked/42
Tempo total: 180ms
Resultados por fonte:
database: 1
cache_after_wait: 99
Como nenhuma abordagem é bala de prata, existem alguns trade-offs que precisamos considerar a respeito do lock distribuído.
-
TTL do lock é uma decisão crítica: Esse valor existe para proteger a aplicação contra um processo que morre segurando o lock, é uma decisão extremamente importante que não nos aprofundaremos aqui, mas saiba que o TTL deve ser maior que o tempo máximo esperado da query no banco, mas pequeno o suficiente pra que uma falha não cause longa indisponibilidade.
-
Polling a cada 50ms: Na nossa aplicação definimos esse valor na constante
const intervalo = 50;, ou seja, a cada 50ms cada uma das requisições que estão aguardando, irão pedir para o Redis se o cache já está pronto, supondo que demore 500ms para que a primeira requisição bata no banco e salve a resposta no cache, seriam ~100 requisições fazendo chamadas ao Redis a cada 50ms, dentro de 500ms seriam 10 chamadas por requisição, ~1000 chamadas ao Redis que poderiam ser evitadas, não nos aprofundaremos aqui, mas você pode pesquisar sobre Redis Pub/Sub.
4. A principal armadilha: Invalidação
Imagine que você cacheou uma informação e ela foi alterada no banco de dados, banco atualiza, cache não, acredito que não há necessidade de uma demonstração visual, você consegue imaginar esse cenário.
A invalidação é algo tão profundo que merece um artigo próprio, aqui ficam as duas estratégias mais comuns:
-
Invalidação explícita: Deleta no cache após o write no banco.
-
TTL curto: O Cache expira dentro de um curto espaço de tempo.
Ambas as abordagens possuem trade-offs, vale estar atento a eles quando for implementar em sua aplicação.
5. Quando não usar Cache?
-
Dados que são mais escritos do que lidos.
-
Dados que precisam ser sempre consistentes (geralmente ligado a financeiro).
-
Alguns bancos possuem uma camada de Cache própria para dados pequenos, é importante estar atento a respeito.
Cache é extremamente poderoso, sem ele a internet da forma que conhecemos não seria nem imaginável, cada uma das armadilhas e trade-offs que abordamos aqui são problemas reais que já derrubaram aplicações robustas.
Nota do Autor:Nenhum prompt foi usado na escrita deste texto.